Every team will setup their CI/CD pipeline differently based on available infrastructure and release policies. The components and tools in any CI/CD pipeline depend on the team’s needs and workflow. At a high level pipelines will have a common structure, which is explained in this article by Deepak Dhami. The four core stages of a pipeline are: source (a change made in an application source code, configuration, environment or data to trigger the pipeline), build, test, and deploy.
“Test data is one of the major bottlenecks in testing processes. By simplifying test data, we can solve this bottleneck by tackling four major challenges.” Provides a solid, high-level view of different types of test data and how each can be leveraged.
This is an excellent how-to on getting k3d and Istio setup locally. The choice is tooling is for a local setup since k3d is a wrapper for k3s in Docker. Additionally the author wants to leverage Keptn for application orchestration. Simple walk through for anyone curious.
Microsoft and GitHub have released a Developer Velocity Lab (DVL), which is a joint research initiative led by Dr. Nicole Forsgren. The DVL aims to discover, improve, and amplify developer work by focusing on productivity, community, and well-being. The first publication is SPACE of Developer Productivity.
The final of a three-part series on GitLab and Jira integration. The final article provides multiple walkthroughs on how to refer Jira issues by the ID in GitLab branch names, commit messages, and merge request titles, as well as the ability to move Jira issues along with commit messages.
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
Teams are likely to get undesired outcomes if they find and fix errors in a separate test phase, executed by a separate QA department only after all development has been completed. Teams should Continuously Build, Test, and Integrate Code Environments.
“Without automated testing, the more code we write, the more time and money is required to test our code—in most cases, this is a totally unscalable business model for any technology organization.”
– Gary Gruver, The DevOps Handbook (Chapter 10)
Google’s own success story on automated testing:
40,000 code commits/day
50,000 builds/day (on weekdays, this may exceed 90,000)
120,000 automated test suites
75 million test cases run daily
100+ engineers working on the test engineering, continuous integration, and release engineering tooling to increase developer productivity (making up 0.5% of the R&D workforce)
Continuously Build, Test, and Integrate Code & Environments
Create automated test suites that increase the frequency of integration and testing of the code and the environments from periodic to continuous.
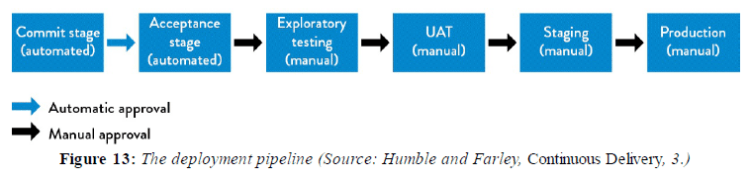
The deployment pipeline, first defined by Jez Humble and David Farley in their book Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation, ensures that all code checked in to version control is automatically built and tested in a production-like environment.
Create automated build and test processes that run in dedicated environments. This is critical for the following reasons:
The build and test process can run all the time, independent of the work habits of individual engineers.
A segregated build and test process ensures that teams understand all the dependencies required to build, package, run, and test the code.
Packaging the application to enable repeatable installation of code and configurations into an environment.
Instead of putting code in packages, teams may choose to package applications into deployable containers.
Environments can be made more production-like in a way that is consistent and repeatable.
The deployment pipeline validates after every change the code successfully integrates into a production-like environment. It becomes the platform through which testers request & certify builds during acceptance testing; the pipeline will run automated performance and security validations.
Adopted from The DevOps Handbook
The goal of a deployment pipeline is to provide everyone in the value stream the fastest possible feedback whether a change is successful or not. Changes could be to the code, any environments, automated tests, or the deployment pipeline infrastructure.
A continuous integration practice requires three capabilities:
A comprehensive and reliable set of automated tests that validate the application is in a deployable state.
A culture that “stops the entire production line” when the validation tests fail.
Developers working in small batches on trunk rather than long-lived feature branches.
Build a Fast and Reliable Automated Validation Test Suite
Unit Tests: These test a single method, class, or function in isolation, providing assurance to the developer that their code operates as designed. Unit tests often “stub out” databases and other external dependencies.
Acceptance Tests: These test the application as a whole to provide assurance that a higher level of functionality operates as designed and that regression errors have not been introduced.
Humble and Farley define the difference between unit and acceptance testing as, “The aim of a unit test is to show that a single part of the application does what the programmer intends it to… the objective of acceptance tests is to prove that our application does what the customer meant it to, not that it works the way its programmers think it should.”
After a build passes unit tests, the deployment pipeline runs the build against acceptance tests. Any build that passes acceptance tests is then typically made available for manual testing.
Integration Tests: Integration tests ensure that the application correctly interacts with other production applications and services, as opposed to calling stubbed out interfaces.
As Humble and Farley observe, “Much of the work in the SIT environment involves deploying new versions of each of the applications until they all cooperate. In this situation the smoke test is usually a fully fledged set of acceptance tests that run against the whole application.”
Integration tests are performed on builds that have passed both the unit and acceptance test suites. Since integration tests are often brittle, teams should minimize the number of integration tests and find defects during unit & acceptance testing. The ability to use virtual or simulated versions of remote services when running acceptance tests becomes an essential architectural requirement.
Catch Errors As Early In The Automated Testing as Possible
For the fastest feedback, it’s important to run faster-running automated tests (unit tests) before slower-running automated tests (acceptance and integration tests), which are both run before any manual testing. Another corollary of this principle is that any errors should be found with the fastest category of testing possible.
Adopted from The DevOps Handbook.
Ensure Tests Run Quickly
Design tests to run in parallel.
Adopted from The DevOps Handbook
Write Automated Tests Before Writing The Code
Use techniques such as test-driven development (TDD) and acceptance test-driven development (ATDD). This is when developers begin every change to the system by first writing an automated test that validates the expected behavior fails and then writes the code to make the tests pass.
Test-Driven Development:
Ensure the tests fail. “Write a test for the next bit of functionality to add.” Check in.
Ensure the tests pass. “Write the functional code until the test passes.” Check in.
“Refactor both new and old code to make it well structured.” Ensure the tests pass. Check in again.
Automate As Many Of The Manual Tests As Possible
Automating all the manual tests may create undesired outcomes – teams should not have automated tests that are unreliable or generate false positives (tests that should have passed because the code is functionally correct but failed due to problems such as slow performance, causing timeouts, uncontrolled starting state, or unintended state due to using database stubs or shared test environments).
A small number of reliable, automated tests are preferable over a large number of manual or unreliable automated tests. Start with a small number of reliable automated tests and add to them over time, creating an increasing level of assurance that any changes to the system that take the application out of a deployable state is detected.
Integrate Performance Testing Into The Test Suite
All too often, teams discover that their application performs poorly during integration testing or after it has been deployed to production. The goal is to write and run automated performance tests that validate the performance across the entire application stack (code, database, storage, network, virtualization, etc.) as part of the deployment pipeline to detect problems early when the fixes are cheapest and fastest.
By understanding how the application and environments behave under a production-like load, the team can improve at capacity planning as well as detecting conditions such as:
When the database query times grow non-linearly.
When a code change causes the number of database calls, storage use, or network traffic to increase.
Integrate Non-Functional Requirements Testing Into The Test Suite
In addition to testing the code functions as designed and it performs under production-like loads, teams should validate every other attribute of the system. These are often called non-functional requirements, which include availability, scalability, capacity, security, etc..
Many nonfunctional requirements rely upon:
Supporting applications, databases, libraries, etc.
Language interpreters, compilers, etc.
Operating systems
Pull The Andon Cord When The Deployment Pipeline Breaks
In order to keep the deployment pipeline in a green state the team should create a virtual Andon Cord, similar to the physical one in the Toyota Production System. Whenever someone introduces a change that causes the build or automated tests to fail, no new work is allowed to enter the system until the problem is fixed.
When the deployment pipeline is broken, at a minimum notify the entire team of the failure, so anyone can either fix the problem or rollback the commit. Every member of the team should be empowered to roll back the commit to get back into a green state.
Why Teams Need To Pull The Andon Cord
The consequence of not pulling the Andon cord and immediately fixing any deployment pipeline issues makes it more difficult to bring applications and environment back into a deployable state.
Consider the following situation:
Someone checks in code that breaks the build or fails automated tests, but no one fixes it.
Someone else checks in another change onto the broken build, which also doesn’t pass the automated tests; however, no one sees the failing test results which would have enabled the team to see the new defect, let alone fix it.
The existing tests don’t run reliably, so the team is unlikely to build new tests.
The negative feedback cycle continues and application quality continues to degrade.
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
The goal is to create the technical practices and architecture required to enable and sustain the fast flow of work from Development into Operations without causing chaos and disruption to the production environment or customers.
Continuous Delivery (CD) includes:
Creating the foundations of the automated deployment pipeline.
Ensuring that the team has automated tests that constantly validate the application is in a deployable state.
Having developers integrate their code into trunk daily.
Architecting the environments and code to enable low-risk releases.
Outcomes of CD:
Reduces the lead time to get production-like environments.
Enables continuous testing that gives everyone fast feedback on their work.
Enables small teams to safely and independently develop, test, and deploy their code into production.
Makes production deployments and releases a routine part of daily work.
Ensure the team always use production-like environments at every stage of the value stream. The environments must be created in an automated manner, ideally on demand from scripts and configuration information stored in version control and entirely self-serviced.
Enable On-Demand Creation of Dev, Test, and Production Environments
Instead of documenting the specifications of the production environment in a document or on a wiki page, the organization should create a common build mechanism that creates all environments, such as for development, test, and production. By doing this, any team can get production-like environments in minutes, without opening up a ticket, let alone having to wait weeks.
Automation can help in the following ways:
Copying a virtualized environment
Building an automated environment creation process
Using “infrastructure as code” configuration management tools
Using automated operating system configuration tools
Assembling an environment from a set of virtual images or containers
Spinning up a new environment in a public cloud, private cloud, or other PaaS (platform as a service)
By providing developers an environment they fully control, teams are enabled to quickly reproduce, diagnose, and fix defects, safely isolated from production services and other shared resources. Teams can also experiment with changes to the environments, as well as to the infrastructure code that creates it (e.g., configuration management scripts), further creating shared knowledge between Development and Operations.
Create a Single Repository of Truth For The Entire System
Use of version control has become a mandatory practice of individual developers and development teams. A version control system records changes to files or sets of files stored within the system. This can be source code, assets, or other documents that may be part of a software development project.
Version Control Recommendations:
All the environment creation tools and artifacts described in the previous step
Any file used to create containers
All supporting automated tests and any manual test scripts
Any script that supports code packaging, deployment, database migration, and environment provisioning
All project artifacts
All cloud configuration files
Any other script or configuration information required to create infrastructure that supports multiple services
Make Infrastructure Easier To Rebuild Than Repair
sds
Any script used to create database schemas or application reference data Bill Baker, a distinguished engineer at Microsoft, quipped that we used to treat servers like pets: “You name them and when they get sick, you nurse them back to health. [Now] servers are [treated] like cattle. You number them and when they get sick, you shoot them.”
The DevOps Handbook, Chapter 9
Instead of manually logging into servers and making changes, make changes in a way that ensures all changes are replicated everywhere automatically and that all changes are put into version control.
Teams can rely on automated configuration systems to ensure consistency, or they can create new virtual machines or containers from an automated build mechanism and deploy them into production, destroying the old ones or taking them out of rotation. This is known as immutable infrastructure.
Modify The Definition of Development “Done” To Include Running in Production-Like Environments
By having developers write, test, and run their own code in a production-like environment, the majority of the work to successfully integrate code and environments happens during daily work, instead of at the end of the release.
Ideally, team will use the same tools, such as monitoring, logging, and deployment, in pre-production environments as they do in production.
Salesforce encountered a global outage after a change applied to DNS servers rendered customer unable to access the products. This occurred because a script to handle a DNS change contained a bug that would cause a timeout under load. Since the change was pushed globally, a timeout occurred and took down Salesforce. What is curious is how the company that prides itself on DevOps practices would allow for one change to take down their applications. Also worrisome is the company threw a single engineer under the bus when it’s apparent that both process and infrastructure could be improved. It won’t encourage other engineers to make changes without covering their butts in the future or have people be forthcoming in postmortems.
In an older post, Art Trevethan advises on how to balance automated and manual testing with an “automate 20% of test cases” approach. He first looks at identifying the test cases that take up an inordinate amount of time, then shifts into the financial aspect of how much value automation provides. Art also provides hood advice on the tools a team should use.
Microsoft has released a Dojo as a Lean Product which requires an inspiring vision, clear mission, focused strategy, human-centric design, and committed execution. They are making DevOps a standard software delivery method at Microsoft Services. The DevOps Dojo is a community of practice at Microsoft that started from the Services organization, and then expanded to Customer Success, Digital Advisory, Product Groups, and other organizations.
Eran Kinsbruner provides insight on how to best leverage Jenkins to help expand automated testing. He first starts by creating a shared understanding of CI/CD and where continuous testing fits. He walks through common challenges to using Jenkins for continuous testing and then provide several patterns to implementation. Eran links a video with a how-to on setting up a pipeline for continuous testing.
GitHub has been at the forefront of security key adoption for many years. They were an early adopter of Universal 2nd Factor (“U2F”) and were also one of the first sites to transition to Webauthn. They’re always on the lookout for new standards that both increase security and usability. GitHub is taking the next step by shipping support for security keys when using Git over SSH.
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
The goal is to enable market-oriented outcomes where many small teams can quickly and independently deliver value to the customer.
Big Fish Games Example: Two types of Ops liaisons: the business relationship manager and the dedicated release engineer.
The business relationship managers worked with product management, line-of-business owners, project management, Dev management, and developers. They became familiar with product group business drivers and product road maps, acted as advocates for product owners inside of Operations, and helped their product teams navigate the Operations landscape to prioritize and streamline work requests.
The dedicated release engineer became intimately familiar with the product’s Development and QA issues, and helped them get what they needed from the Ops organization to achieve their goals. They would also pull in dedicated technical Ops engineers (e.g., DBAs, Infosec, storage engineers, network engineers) and help determine which self-service tools the entire Operations group should prioritize building.
Strategies for a centralized Ops team to be successful:
Create self-service capabilities to enable developers in the service teams to be productive.
Embed Ops engineers into the service teams.
Assign Ops liaisons to the service teams when embedding Ops is not possible.
Create Shared Services to Increase Developer Productivity
One way to enable market-oriented outcomes is for Operations to create a set of centralized platforms and tooling services that any Dev team can use to become more productive, such as getting production-like environments, deployment pipelines, automated testing tools, production telemetry dashboards, and so forth.
Example: a platform that provides a shared version control repository with pre-blessed security libraries, a deployment pipeline that automatically runs code quality and security scanning tools, which deploys our applications into known, good environments that already have production monitoring tools installed on them.
Creating and maintaining these platforms and tools is real product development.
Internal shared services teams should continually look for internal toolchains that are widely being adopted in the organization, deciding which ones make sense to be supported centrally and made available to everyone.
Embed Ops Engineers into Service Teams
Enable product teams to become more self-sufficient by embedding Operations engineers within them, thus reducing their reliance on centralized Operations.
“In many parts of Disney we have embedded Ops (system engineers) inside the product teams in our business units, along with inside Development, Test, and even Information Security. It has totally changed the dynamics of how we work. As Operations Engineers, we create the tools and capabilities that transform the way people work, and even the way they think. In traditional Ops, we merely drove the train that someone else built. But in modern Operations Engineering, we not only help build the train, but also the bridges that the trains roll on.”
Jason Cox
Assign An Ops Liaison To Each Service Team
One option instead of embedding an Ops engineer into every product team is assigning a designated liaison for each product team.
The designated Ops engineer is responsible for understanding:
What the new product functionality is and why we’re building it.
How it works as it pertains to operability, scalability, and observability (diagramming is strongly encouraged).
How to monitor and collect metrics to ensure the progress, success, or failure of the functionality.
Any departures from previous architectures and patterns, and the justifications for them.
Any extra needs for infrastructure and how usage will affect infrastructure capacity.
Feature launch plans.
Integrate Ops Into Dev Rituals
When Ops engineers are embedded or assigned as liaisons into product teams, they can be integrated into Dev team rituals. For instance, the Daily Standup, which is a quick meeting where everyone on the team gets together and presents to each other three things: what was done yesterday, what is going to be done today, and what is preventing you from getting your work done.
The purpose of this ceremony is to radiate information throughout the team and to understand the work that is being done and is going to be done. By having Ops engineers attend, Operations can gain an awareness of the Development team’s activities, enabling better planning and preparation.
Invite Ops To Dev Retrospectives
The Retrospective: At the end of each development interval, the team discusses what was successful, what could be improved, and how to incorporate the successes and improvements in future iterations or projects.
Having Ops engineers attend project team retrospectives means they can also benefit from any new learnings. Feedback from Operations helps the product teams better see and understand the downstream impact of decisions they make.
Make Relevant Ops Work Visible on Shared Kanban Boards
Because Operations is part of the product value stream, teams should put the Operations work that is relevant to product delivery on the shared Kanban Board.
This enables teams to more clearly see all the work required to move code into production. It enables teams to see where Ops work is blocked and where work needs escalation, highlighting areas where the team may need improvement.
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
Conway’s Law: “organizations which design systems… are constrained to produce designs which are copies of the communication structures of these organizations…The larger an organization is, the less flexibility it has and the more pronounced the phenomenon.”
How teams are organized has a powerful effect on the software produced as well as resulting architectural and production outcomes.
Conway’s Law Example: Sprouter at Etsy. Sprouter is shorthand for stored procedure router. Sprouter resided between their front-end PHP application and the Postgres database, centralizing access to the database and hiding the database implementation from the application layer.
“Sprouter was designed to allow the Dev teams to write PHP code in the application, the DBAs to write SQL inside Postgres, with Sprouter helping them meet in the middle.”
Etsy case study, Chapter 7
The problem with Sprouter? Any changes to business logic meant the DBAs had to write a new stored procedure. Developers creating new functionality had a dependency on the DBA team; required prioritization, communication, and coordination.
Etsy changed by investing into site stability, having developers perform their own deployments into production, and the retirement of Sprouter.
They wrote a PHP Object Relation Mapping (ORM) layer that allowed front-end developers to make calls directly to the database and reduced the number of teams required to change business logic (from 3 teams to 1 team).
Organizational Archetypes
Three primary types of organization structures for DevOps value streams: functional, matrix, and market.
Functional-oriented Organizations optimize for expertise, division of labor, or reducing cost. Characterized by centralized expertise, which helps enable career growth and skill development, as well as tall hierarchical organizational structures.
Matrix-oriented Organizations attempt to combine functional and market orientation. Matrix organizations can result in complicated organizational structures, such as individual contributors reporting to two managers or more.
Market-oriented Organizations optimize for responding quickly to customer needs. These organizations tend to be flat and composed of multiple, cross-functional disciplines.
Problems Often Caused By Overly Functional Orientation (“Optimizing For Cost”)
Typical problems include:
Teams are organized by specialties, which leads to long lead times as groups coordinate work handoffs.
Teams are in a creativity and motivation vacuum because they can’t see the bigger picture.
When each Operations area must serve multiple value streams who compete for their cycles, the troubles are exacerbated.
Characterized by long queues & long lead times with poor handoffs & lots of rework.
Issues scaling with more frequent releases.
Enable Market-Oriented Teams (“Optimizing For Speed”)
Typical aspects of market-oriented teams include:
Many small teams working safely and independently, quickly delivering value to the customer.
Market-oriented teams are responsible not only for feature development, but also for testing, securing, deploying, and supporting their service in production, from idea conception to retirement.
Cross-functional and independent; design, build & deliver new features, deploy & run their service in production, and fix defects with minimal dependencies.
Embedded functional engineers and skills (Ops, QA, Infosec) into each service team.
Adopted from The DevOps Handbook
Making Functional Orientation Work
Achievement of DevOps goals is possible with functional orientation so long as everyone in the value stream views customer and organizational outcomes as the shared goal.
Many of the most admired DevOps organizations retain functional orientation of Operations, including Etsy, Google, and GitHub.
“As tempting as it seems, one cannot reorganize your way to continuous improvement and adaptiveness. What is decisive is not the form of the organization, but how people act and react.”
Mike Rother, Toyota Kata
Testing, Operations, and Security As Everyone’s Job, Every Day
In high-performing organizations, everyone within the team shares a common goal—quality, availability, and security aren’t the responsibility of individual departments but are a part of everyone’s job, every day.
Shared pain can reinforce shared goals. Facebook Example: In 2009 they had problems related to code deployments. In a meeting full of Ops engineers where someone asked that all people not working on an incident close their laptops, and no one could.
The solution: all Facebook engineers, engineering managers, and architects rotate through on-call duty for the services they built.
Enable Every Team Member To Be A Generalist
When departments over-specialize, it causes siloization.
Siloization: when departments operate more like sovereign states. Complex operational activity then requires multiple handoffs and queues between the different areas of the infrastructure, leading to longer lead times.
Don’t create specialists who are “frozen in time,” only understanding and able to contribute to that one area of the value stream. Instead, provide opportunities to learn all skills necessary to build and run the systems teams are responsible for; this includes regularly rotating roles.
Adopted from the DevOps Handbook
When people are valued merely for their existing skills or performance in their current role rather than for their ability to acquire and deploy new skills, the organization has what Dr. Carol Dweck describes as the fixed mindset, where people view their intelligence and abilities as static “givens” that can’t be changed in meaningful ways.
Encourage learning and ensure people have relevant skills & a defined career road map. This fosters a “growth mindset”. The organization must provide training and support to create a sustainable team.
Fund Not Projects, But Services and Products
Another way to enable high-performing outcomes is to create stable service teams with ongoing funding to execute their own strategy and road map of initiatives.
The more traditional model has Development and Test teams assigned to a “project” and then reassigned to another project as soon as the project is completed, and funding runs out.
The goal of a product-based funding model is to value the achievement of organizational and customer outcomes, such as revenue, customer lifetime value, or customer adoption rate, ideally with the minimum of output.
Design Team Boundaries In Accordance With Conway’s Law
As organizations grow, one of the largest challenges is maintaining effective communication and coordination between people and teams. Collaboration is also impeded when the primary communication mechanisms are work tickets and change requests.
Software architecture should enable small teams to be independently productive, sufficiently decoupled from each other so that work can be done without excessive or unnecessary communication and coordination.
Create Loosely-Coupled Architectures To Enable Developer Productivity and Safety
With tightly-coupled architecture, small changes can result in large scale failures. The result is not only long lead times for changes (typically measured in weeks or months) but also low developer productivity and poor deployment outcomes.
Architecture that enables small teams of developers to independently implement, test, and deploy code into production safely and quickly, can increase and maintain developer productivity and improve deployment outcomes. Having architecture that is loosely-coupled means that services can update in production independently, without having to update other services.
Keep Team Sizes Small (The “Two-Pizza Team” Rule)
As part of its transformation initiative away from a monolithic code base in 2002, Amazon used the two-pizza rule to keep team sizes small—a team only as large as can be fed with two pizzas—usually about five to ten people.
Small Team Size Benefits:
Teams have a clear, shared understanding of the system they’re working on.
Limits the growth rate of the product or service being worked on.
Decentralizes power and enables autonomy.
Employees gain leadership experience in an environment where failure does not have catastrophic consequences.
In a just-released podcast, Joe Colantonio chats with Gaspar Nagy & Seb Rose on their new book, Formulation. The book is the second in a series of three books on Behavior Driven Development. Formulation is focused on how you get all stakeholders involved in the creation of production specifications. It’s a great listen for two of the thought leaders on BDD in the community.
The post from CloudBees covers the principles of CI/CD including the key components and how they work. The main point of CI/CD is to deliver code faster by automatically integrate and test the new code before deployment. The post provide key definitions on CI and CD followed by descriptions of Build, Test, and Deployment phases of a pipeline. A good intro for beginners.
Rehan Saeed presents a few tools to use for unit testing and frontend testing currently in use by his team. Jest is a unit testing framework built by Facebook; it’s a single NPM package that includes an assertion library, mocking framework, and code coverage tools Rehan also briefly covers Cypress, which is a frontend web testing tool.
Paul Grizzaffi makes the case that automation should be approached from the perspective of business value. Two factors that should be considered are opportunity cost and total cost of ownership. Maintenance costs should be included in the total cost of an automation initiative (maintenance includes bug fixes, work to maintain application parity, infrastructure upgrades, etc.).
Eran Kinsbruner covers four emerging mobile trends. The first is Apple App Clips, which allows users to download a subset of an app rather than the entire thing. Android APKs are a an format that consume fewer resources in phones such as battery and CPU. Foldables have also become more popular, with releases from Microsoft, Samsung, LG, and Huawei. PWAs are responsive web apps with mobile specific abilities (however they do not has full support from Apple).
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
Identify all the teams required to create customer value
Create a value stream map to make visible all the required work
Use the map to guide the teams in how to better and more quickly create value
Identifying The Teams Supporting Our Value Stream
No one person knows all the work that must be performed in order to create value for the customer.
Select a candidate application or service for the DevOps initiative, identify all the members of the value stream who are responsible for working together to create value for the customers being served.
All members of the value stream responsible for working together to create value for the customers being served must be identified.
Product Owner: the internal voice of the business that defines the next set of functionality in the service.
Development: the team responsible for developing application functionality in the service.
QA: the team responsible for ensuring that feedback loops exist to ensure the service functions as desired.
Operations: the team often responsible for maintaining the production environment and helping ensure that required service levels are met.
Infosec: the team responsible for securing systems and data.
Release Managers: the people responsible for managing and coordinating the production deployment and release processes.
Technology Executives or Value Stream Manager: in Lean literature, someone who is responsible for “ensuring that the value stream meets or exceeds the customer [and organizational] requirements for the overall value stream, from start to finish”.
Create A Value Stream Map To See The Work
The value stream focuses on (1) places where work must wait weeks or even months, such as getting production-like environments, change approval processes, or security review processes; and (2) places where significant rework is generated or received.
The first step is to identify high-level process blocks. Each process block includes the lead time and process time for a work item to be processed.
Adopted from the DevOps Handbook
Identify the metric that needs to be improved and then perform the next level of observations and measurements to understand the problem and construct the idealized, future value stream map.
Creating a Dedicated Transformation Team
The team must be accountable for achieving a clearly defined, measurable, system-level result (such as reducing deployment lead time from “code committed into version control to successfully running in production”).
To be successful, the transformation team should:
Assign members of the dedicated team to be solely allocated to the DevOps transformation efforts (as opposed to “maintain all your current responsibilities but spend 20% of your time on this new DevOps thing”).
Select team members who are generalists, who have skills across a wide variety of domains.
Select team members who have longstanding and mutually respectful relationships with the rest of the organization.
Create a separate physical space for the dedicated team, if possible, to maximize communication flow within the team, and create some isolation from the rest of the organization.
Agree On A Shared Goal
Agree upon a clearly defined deadline and a goal.
Improvement Goals include:
Reduce the percentage of the budget spent on product support and unplanned work by 50%.
Ensure lead time from code check-in to production release is one week or less for 95% of changes.
Ensure releases can always be performed during normal business hours with zero downtime.
Integrate all the required information security controls into the deployment pipeline to pass all required compliance requirements.
Keep The Improvement Planning Horizons Short
The initiative should generate measurable improvements or actionable data within weeks.
Short planning horizons and iteration intervals achieve the following:
Flexibility and the ability to reprioritize and replan quickly.
Decrease the delay between work expended and improvement realized, which strengthens our feedback loop, making it more likely to reinforce desired behaviors. When improvement initiatives are successful, it encourages more investment.
Faster learning generated from the first iteration, meaning faster integration of learnings into the next iteration.
Reduction in activation energy to get improvements.
Quicker realization of improvements that make meaningful differences in daily work.
Less risk that our project is killed before we can generate any demonstrable outcomes.
Reserve 20% of Cycles For Non-Functional Requirements and Reducing Technical Debt
Organizations that don’t pay down technical debt can find themselves so burdened with daily workarounds for problems left unfixed that they can no longer complete any new work.
Adopted from the DevOps Handbook
Increase The Visibility of Work
In order to be able to know if we are making progress toward our goal, it’s essential that everyone in the organization knows the current state of work.
Use Tools to Increase Desired Behavior
“Anthropologists describe tools as a cultural artifact. Any discussion of culture after the invention of fire must also be about tools.”
Christopher Little
Similar to Anthropologists, in the DevOps value stream teams use tools to reinforce culture and accelerate desired behavior changes.
Tooling reinforces that Development and Operations have shared goals and a common backlog of work. Common work system and shared vocabulary such as a unified backlog where work is prioritized from a global perspective is a benefit to the organization
Other technologies that reinforce shared goals? Chat Rooms. However, the expectations of immediate response means a barrage of interruptions and questions.
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
Choosing a value stream for DevOps transformation deserves careful consideration. The value stream chosen dictates the difficulty of the transformation and also dictates who will be involved in the transformation. The value stream will affect how the organization will organize into teams and how to best enable the teams & individuals in them.
Nordstrom DevOps Case Study
Nordstrom focused on three areas in their DevOps transformation:
The customer mobile application
Their in-store restaurant systems
Their digital properties
Each of the above areas had business goals that weren’t being met, so as an organization they were more receptive to considering a different way of working. For instance, the poorly designed mobile app only released 2x per year.
Nordstrom Solutions:
Dedicated team for the mobile app (independent development, testing, deployment)
Integrated testing into everyone’s daily work
Altered work intake and deployment processes for in-store restaurant app that reduced deployment lead times and production incidents.
Value Stream Mapping
Reducing Batch Sizes
Continuous Delivery
Greenfield versus Brownfield Services
Greenfield Development is when we build on undeveloped land.
Brownfield Development is when we build on land that was previously used for industrial purposes, potentially contaminated with hazardous waste or pollution.
The DevOps Handbook. Chapter 5.
In technology, a greenfield project is a new software project or initiative, likely in the early stages of planning or implementation, where applications and infrastructure are built anew with few constraints. Brownfield projects often come with significant amounts of technical debt, such as having no test automation or running on unsupported platforms.
One of the findings in the 2015 State of DevOps Report validated that the age of the application was not a significant predictor of performance. Instead, whether the application was architected for testability and deployability was a better predictor for performance.
Consider Both Systems of Record and Systems of Engagement
Bimodal IT refers to the wide spectrum of services that typical enterprises support.
Systems of Record are the ERP-like systems that run business (e.g., HR, financial reporting systems), where the correctness of the transactions and data are paramount. Typically, regulatory and compliance issues.
Systems of Engagement are customer-facing or employee-facing systems, such as e-commerce systems and productivity applications.
Start With The Most Sympathetic and Innovative Groups
In “Crossing The Chasm” by Geoffrey A. Moore, the chasm represents the classic difficulty of reaching groups beyond the innovators and early adopters.
The DevOps Handbook. Chapter 5 Figure 9
Expanding DevOps Across The Organization
To build a DevOps culture, identify and work with the following groups in this order:
Find Innovators and Early Adopters
Build Critical Mass and Silent Majority
Identify the Holdouts
Find Innovators and Early Adopters
In the beginning, focus efforts on teams who actually want to help. These groups are typically the first to volunteer to start the DevOps journey. In an ideal state these people are respected and have a high degree of influence over the rest of the organization, giving the initiative more credibility.
Build Critical Mass and Silent Majority
In the next phase, seek to expand DevOps practices to more teams and value streams with the goal of creating a stable base of support. By working with teams who are receptive to new ideas, the coalition is expanded and ultimately generates more success, creating a “bandwagon effect” that further increases influence. It’s recommended to specifically bypass dangerous political battles that could jeopardize the initiative.
Identify the Holdouts
The “holdouts” are the high profile, influential detractors who are most likely to resist the DevOps transformation efforts. In general, approach this group only after having achieved a silent majority, when the DevOps transformation has established enough successes to successfully protect the initiative.
The State of Testing report is an annual survey released by PractiTest that seeks to identify the current characteristics, practices, and challenges facing the software testing community. This year’s survey found that the size of the software testers teams is growing in organizations. Additionally, close to 90% of organizations implementing test automation as part of their integrated software QA approach. Teams are also using automation in building and deploying software, with 85% of organizations adopting some form of DevOps practice. The full report is available HERE.
Acceptance test-driven development is a whole-delivery cycle method that allows the entire team to define system behavior in specific terms before coding begins. These conversations align the expectations of the testers, developers, and product owners, forcing any silly arguments to happen before someone has to create the code twice. Here are some great beginner exercises for teaching ATDD.
Incomplete logs cause a lack of information, visibility, trackability, and context. Pawel encourages teams to look for patterns and turn the raw data from logs into metrics. He recommends using a structured logging approach, so they will be better processed programmatically to provide insights. To convert logs into usable format, use a time series database to parse the information in the context of monitoring and then count everything in specific timeframes.
GitLab has published a remote work report in response to the massive shift to working from home during COVID. They found that half of all workers would consider leaving their current company for a remote role. Even though a majority of people would recommend working remotely to a friend, nearly all people polled are not satisfied with their level of productivity. Only one third of workers report their organization does a good job of aligning work across projects. Given the current restrictions on office work, 33% of remote workers saw their company implement a virtual coffee or tea break to foster a sense of community.
Eran Kinsbruner provides some advice on getting the most Return On Investment (ROI) on the software testing budget. The first place he recommends exploring is everything being tested manually and converting as many repetitive tests to automated tasks. He also recommends aligning automation frameworks to skillsets in the organization. The full list of his recommendations for improvement are located in the linked article.