
- Book Club: The DevOps Handbook (Conclusion)
- Book Club: The DevOps Handbook (Chapter 23. Protecting the Deployment Pipeline and Integrating Into Change Management and Other Security and Compliance Controls)
- Book Club: The DevOps Handbook (Chapter 22. Information Security as Everyone’s Job, Every Day)
- Book Club: The DevOps Handbook (Chapter 21. Reserve Time to Create Organizational Learning and Improvement)
- Book Club: The DevOps Handbook (Chapter 20. Convert Local Discoveries into Global Improvements)
- Book Club: The DevOps Handbook (Chapter 19. Enable and Inject Learning into Daily Work)
- Book Club: The DevOps Handbook (Chapter 18. Create Review and Coordination Processes to Increase Quality of Our Current Work)
- Book Club: The DevOps Handbook (Chapter 17. Integrate Hypothesis-Driven Development and A/B Testing into Our Daily Work)
- Book Club: The DevOps Handbook (Chapter 16. Enable Feedback So Development and Operations Can Safely Deploy Code)
- Book Club: The DevOps Handbook (Chapter 15. Analyze Telemetry to Better Anticipate Problems and Achieve Goals)
- Book Club: The DevOps Handbook (Chapter 14. Create Telemetry to Enable Seeing and Solving Problems)
- Book Club: The DevOps Handbook (Chapter 13. Architect for Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 12. Automate and Enable Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 11. Enable and Practice Continuous Integration)
- Book Club: The DevOps Handbook (Chapter 10. Enable Fast and Reliable Automated Testing)
- Book Club: The DevOps Handbook (Chapter 9. Create the Foundations of our Deployment Pipeline )
- Book Club: The DevOps Handbook (Chapter 8. How to Get Great Outcomes by Integrating Operations into the Daily Work of Development)
- Book Club: The DevOps Handbook (Chapter 7. How to Design Our Organization and Architecture with Conway’s Law in Mind)
- Book Club: The DevOps Handbook (Chapter 6. Understanding the Work in Our Value Stream, Making it Visible, and Expanding it Across the Organization)
- Book Club: The DevOps Handbook (Chapter 5. Selecting Which Value Stream to Start With)
- Book Club: The DevOps Handbook (Chapter 4. The Third Way: The Principles of Continual Learning and Experimentation)
- Book Club: The DevOps Handbook (Chapter 3. The Second Way: The Principles of Feedback)
- Book Club: The DevOps Handbook (Chapter 2. The First Way: The Principles of Flow)
- Book Club: The DevOps Handbook (Chapter 1. Agile, Continuous Delivery, and the Three Ways)
- Book Club: The DevOps Handbook (Introduction)
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
The DevOps Handbook
Chapter 16
The goal is to catch errors in the deployment pipeline before they get into production. However, there will still be errors teams don’t detect, and so they must rely on production telemetry to quickly restore service.
Solutions available to teams:
- Turn off broken features with feature toggles
- Fix forward (make code changes to fix the defect that are pushed into production through the deployment pipeline)
- Roll back (switch back to the previous release by taking broken servers out of rotation using the blue-green or canary release patterns)
Since production deployments are one of the top causes of production issues, each deployment and change event is overlaid onto our metric graphs to ensure that everyone in the value stream is aware of relevant activity, enabling better communication and coordination, as well as faster detection and recovery.
Developers Share Production Duties With Operations
Even when production deployments and releases go flawlessly, in any complex service there will still have unexpected problems, such as incidents and outages that happen at inopportune times. Even if the problem results in a defect being assigned to the feature team, it may be prioritized below the delivery of new features.
As Patrick Lightbody, SVP of Product Management at New Relic, observed in 2011, “We found that when we woke up developers at 2 a.m., defects were fixed faster than ever.” This practice helps Development management see that business goals are not achieved simply because features have been marked as “done”. Instead, the feature is only done when it is performing as designed in production, without causing excessive escalations or unplanned work for either Development or Operations.
When developers get feedback on how their applications perform in production, which includes fixing it when it breaks, they become closer to the customer.
Have Developers Follow Work Downstream
One of the most powerful techniques in interaction and user experience design (UX) is contextual inquiry. This is when the product team watches a customer use the application in their natural environment, often working at their desk. Doing so often uncovers ways that customers struggle with the application, such as:
- Requiring scores of clicks to perform simple tasks in their daily work
- Cutting and pasting text from multiple screens
- Writing down notes on paper
Developers should follow their work downstream, so they can see how downstream work centers must interact with their product to get it running into production. Teams create feedback on the non-functional aspects of our code and identify ways to improve deployability, manageability, operability, etc.
Have Developers Initially Self-Manage Their Production Service
Even when Developers are writing and running their code in production-like environments in their daily work, Operations may still experience disastrous production releases because it’s the first time the application is under true production conditions. This result occurs because operational learnings often occur too late in the software life cycle.
One potential countermeasure is to do what Google does, which is have Development groups self-manage their services in production before they become eligible for a centralized Ops group to manage. By having developers be responsible for deployment and production support, teams are more likely to have a smooth transition to Operations.
Teams could define launch requirements that must be met in order for services to interact with real customers and be exposed to real production traffic.
Launch Guidance:
- Defect counts and severity: Does the application actually perform as designed?
- Type/frequency of pager alerts: Is the application generating an unsupportable number of alerts in production?
- Monitoring coverage: Is the coverage of monitoring sufficient to restore service when things go wrong?
- System architecture: Is the service loosely-coupled enough to support a high rate of changes and deployments in production?
- Deployment process: Is there a predictable, deterministic, and sufficiently automated process to deploy code into production?
- Production hygiene: Is there evidence of enough good production habits that would allow production support to be managed by anyone else?
Google’s Service Handback Mechanism
When a production service becomes sufficiently fragile, Operations has the ability to return production support responsibility back to Development. When a service goes back into a developer-managed state, the role of Operations shifts from production support to consultation, helping the team make the service production-ready.

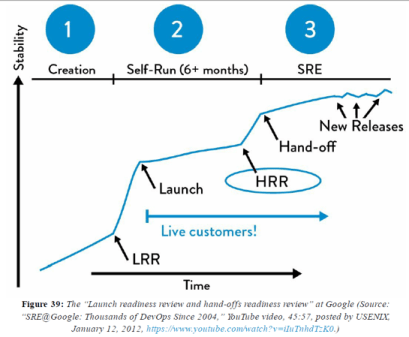
Google created two sets of safety checks for two critical stages of releasing new services called the Launch Readiness Review and the Hand-Of Readiness Review. The LRR must be performed and signed off on before any new Google service is made publicly available to customers and receives live production traffic. The HRR is performed when the service is transitioned to an Ops-managed state. The HRR is far more stringent and has higher acceptance standards.
The practice of SREs helping product teams early is an important cultural norm that is continually reinforced at Google. Helping product teams is a long-term investment that will pay off many months later when it comes time to launch. It is a form of ‘good citizenship’ and ‘community service’ that is valued, it is routinely considered when evaluating engineers for SRE promotions.
Common Regulatory Concerns to Answer
- Does the service generate a significant amount of revenue?
- Does the service have high user traffic or have high outage/impairment costs?
- Does the service store payment cardholder information, such as credit card numbers, or personally identifiable information, such as Social Security numbers or patient care records? Are there other security issues that could create regulatory, contractual obligation, privacy, or reputation risk?
- Does the service have any other regulatory or contractual compliance requirements associated with it, such as US export regulations, PCI-DSS, HIPAA, and so forth?