
- Book Club: The DevOps Handbook (Conclusion)
- Book Club: The DevOps Handbook (Chapter 23. Protecting the Deployment Pipeline and Integrating Into Change Management and Other Security and Compliance Controls)
- Book Club: The DevOps Handbook (Chapter 22. Information Security as Everyone’s Job, Every Day)
- Book Club: The DevOps Handbook (Chapter 21. Reserve Time to Create Organizational Learning and Improvement)
- Book Club: The DevOps Handbook (Chapter 20. Convert Local Discoveries into Global Improvements)
- Book Club: The DevOps Handbook (Chapter 19. Enable and Inject Learning into Daily Work)
- Book Club: The DevOps Handbook (Chapter 18. Create Review and Coordination Processes to Increase Quality of Our Current Work)
- Book Club: The DevOps Handbook (Chapter 17. Integrate Hypothesis-Driven Development and A/B Testing into Our Daily Work)
- Book Club: The DevOps Handbook (Chapter 16. Enable Feedback So Development and Operations Can Safely Deploy Code)
- Book Club: The DevOps Handbook (Chapter 15. Analyze Telemetry to Better Anticipate Problems and Achieve Goals)
- Book Club: The DevOps Handbook (Chapter 14. Create Telemetry to Enable Seeing and Solving Problems)
- Book Club: The DevOps Handbook (Chapter 13. Architect for Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 12. Automate and Enable Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 11. Enable and Practice Continuous Integration)
- Book Club: The DevOps Handbook (Chapter 10. Enable Fast and Reliable Automated Testing)
- Book Club: The DevOps Handbook (Chapter 9. Create the Foundations of our Deployment Pipeline )
- Book Club: The DevOps Handbook (Chapter 8. How to Get Great Outcomes by Integrating Operations into the Daily Work of Development)
- Book Club: The DevOps Handbook (Chapter 7. How to Design Our Organization and Architecture with Conway’s Law in Mind)
- Book Club: The DevOps Handbook (Chapter 6. Understanding the Work in Our Value Stream, Making it Visible, and Expanding it Across the Organization)
- Book Club: The DevOps Handbook (Chapter 5. Selecting Which Value Stream to Start With)
- Book Club: The DevOps Handbook (Chapter 4. The Third Way: The Principles of Continual Learning and Experimentation)
- Book Club: The DevOps Handbook (Chapter 3. The Second Way: The Principles of Feedback)
- Book Club: The DevOps Handbook (Chapter 2. The First Way: The Principles of Flow)
- Book Club: The DevOps Handbook (Chapter 1. Agile, Continuous Delivery, and the Three Ways)
- Book Club: The DevOps Handbook (Introduction)
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
The DevOps Handbook
Chapter 2
The First Way requires the fast and smooth flow of work from Development to Operations, to deliver value to customers quickly. Flow is increased by making work visible, by reducing batch sizes and intervals of work, and by building quality in, preventing defects from being passed to downstream work centers. The ultimate goal is to decrease the amount of time required for changes to be deployed into production and to increase the reliability and quality of those services.
Make Work Visible
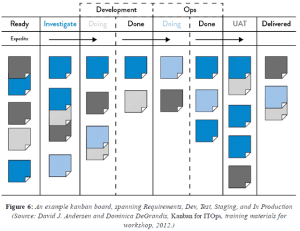
A significant difference between technology and manufacturing value streams is that work is invisible. Work can bounce between teams due to incomplete information, or work can be passed onto downstream work centers with problems that remain invisible. One of the best methods of making work visible is by using boards to track work, such as Kanban boards or sprint planning boards, where work is represented on physical or electronic cards.
Kanban
In Kanban, work flows from left to right. Measure lead time from when a card is placed on the board to when it is moved into the “Done” column. Work is DONE when it reaches production.
Limit Work in Progress (WIP)
In technology, work is usually far more dynamic. This is especially the case in shared services, where teams must satisfy the demands of many different stakeholders. Often daily work becomes dominated by recency priority, with requests for urgent work coming in through every communication mechanism possible, including ticketing systems, outage calls, emails, phone calls, chat rooms, and management escalations.
Interrupting technology workers is easy, because the consequences are often invisible. Multitasking can be limited by using a Kanban board to manage work, by enforcing WIP (work in progress) limits for each column or work center that puts an upper limit on the number of cards that can be in a column. For example, limit the number of cards in a given column. Limiting WIP also makes it easier to visually identify problems that prevent the completion of work.
Reduce Batch Sizes
Another key component to creating smooth and fast flow is performing work in small batch sizes. The theoretical lower limit for batch size is single-piece flow, where each operation is performed one unit at a time.
The negative outcomes associated with large batch sizes are just as relevant to the technology value stream as in manufacturing. The larger the change going into production, the more difficult the production errors are to diagnose and fix, and the longer they take to remediate.

Reduce The Number of Handoffs
To transmit code through the value stream requires multiple departments to work on a variety of tasks, including functional testing, integration testing, environment creation, server administration, storage administration, networking, load balancing, and information security.
A recommended approach is to automate significant portions of the work or to reorganize teams so they can deliver value to the customer themselves instead of having to be constantly dependent on others.
Continually Identify and Elevate Constraints
To reduce lead times and increase throughput, teams should continually identify the system’s constraints and improve its work capacity.
“In any value stream, there is always a direction of flow, and there is always one and only one constraint; any improvement not made at that constraint is an illusion.”
Beyond the Goal by Eli Goldratt
Five Focusing Steps to Address Constraints
- Identify the system’s constraint.
- Decide how to exploit the system’s constraint.
- Subordinate everything else to the above decisions.
- Elevate the system’s constraint.
- If in the previous steps a constraint has been broken, go back to step one, but do not allow inertia to cause a system constraint.
DevOps Constraint Progression
Environment Creation: On-demand deployments are not achievable if the wait time is weeks or months for production or test environments. The countermeasure is to create environments that are on demand and completely self-serviced, so that they are always available when we need them.
Code Deployment: On-demand deployments are not possible if each of the production code deployments take weeks or months to perform. The countermeasure is to automate our deployments as much as possible, with the goal of being completely automated so they can be done self-service by any developer.
Test Setup and Run: On-demand deployments are not possible if every code deployment requires two weeks to set up the test environments and data sets, and another four weeks to manually execute all our regression tests. The countermeasure is to automate our tests to can execute deployments safely and to parallelize them so the test rate can keep up with the code development rate.
Overly Tight Architecture: On-demand deployments are not possible if overly tight architecture means that every time a code change occurs the engineers must attend scores of committee meetings in order to get permission to make changes. The countermeasure is to create more loosely-coupled architecture so that changes can be made safely and with more autonomy, increasing developer productivity.
Eliminate Hardships and Waste in The Value Stream
Modern interpretations of Lean have noted that “eliminating waste” can have a demeaning and dehumanizing context; instead, the goal is reframed to reduce hardship and drudgery in daily work through continual learning in order to achieve the organization’s goals.
Categories of Waste and Hardship
Partially Done Work: Any work in the value stream that has not been completed (requirement documents or change orders not yet reviewed) and work that is sitting in queue (waiting for QA review or admin tickets). Partially done work becomes obsolete and loses value as time progresses.
Extra Processes: Any additional work being performed in a process that does not add value to the customer. This may include documentation not used in a downstream work center or reviews or approvals that do not add value to the output. Extra processes add effort and increase lead times.
Extra Features: Features built into the service that are not needed by the organization or the customer (“gold plating”). Extra features add complexity and effort to testing and managing functionality.
Task Switching: When people are assigned to multiple projects and value streams, requiring them to context switch and manage dependencies between work, adding additional effort and time into the value stream.
Waiting: Any delays between work requiring people to wait until they can complete the current work. Delays increase cycle time and prevent the customer from getting value.
Motion: The amount of effort to move information or materials from one work center to another. Motion waste can be created when people who need to communicate frequently are not co-located. Handoffs also create motion waste and often require additional communication to resolve ambiguities.
Defects: Incorrect, missing, or unclear information, materials, or products create waste, as effort is needed to resolve these issues. The longer the time between defect creation and defect detection, the more difficult it is to resolve the defect.
Nonstandard or Manual Work: Reliance on nonstandard or manual work from others, such as using non-rebuilding servers, test environments, and configurations. Ideally, any dependencies on Operations should be automated, self-serviced, and available on demand.
Heroics: In order for an organization to achieve goals, individuals and teams are put in a position where they must perform unreasonable acts, which may even become a part of their daily work (nightly 2AM problems in production, creating hundreds of work tickets as part of every software release).